Les deux unités de base dans chaque ordinateur d'aujourd'hui sont le bit et l' octet. Un octet est pour les systèmes habituels d'aujourd'hui défini comme une suite de 8 bits (on parle aussi de bytes). Étant donné que chaque bit peut avoir deux états à savoir 0 ou 1 ou bien oui ou non, il est possible de réaliser avec une suite de 8 bits exactement 256 (= 28) états différents. Étant donné que dans l'ordinateur le comptage commence toujours à 0, vous pouvez avoir dans un octet des valeurs décimales comprises entre 0 et 255.
Quand un programme qui tourne sur l'ordinateur lit signe par signe un fichier dans la mémoire de travail, se trouvent ensuite dans la mémoire de travail que des valeurs d'octets. Si donc un navigateur WWW lit un fichier HTML dans la mémoire de travail, le fichier n'y est composé de rien d'autre que de valeurs d'octets. À ce niveau, il n'est pas encore question des signes de notre alphabet. Pour que les valeurs d'octet deviennent des signes lisibles pouvant être représentés à l'écran, il faut une convention qui établit quelle valeur d'octet doit représenter quel signe. C'est le travail de ce qu'on appelle les jeux de caractères. Les jeux de caractères sont des tableaux qui affectent un signe ayant une signification dans nos cultures d'écritures.
Les jeux de caractères sont des créations anciennes dans l'histoire de l'informatique. Jusqu'à l'arrivée de l'ordinateur personnel, beaucoup d'ordinateurs utilisaient encore des unités de base de 7 bits, avec lesquelles on ne pouvait représenter que 128 états différents. Encore plus tôt, on a eu aussi des unités de base de 6 bits et de 5 bits de long. Les premiers jeux de caractères s'étant imposés historiquement, reposent sur les unités de base de 7 bits : le jeu de caractères ASCII et le jeu de caractères EBCDIC. Là c'est avant tout le jeu de caractères ASCII qui s'imposait parce qu'il fut mis en service dans le système d'exploitation en vogue Unix et sur les ordinateurs personnels.
Pour le jeu de caractères ASCII les 32 premiers signes sont réservés pour des caractères de contrôle, par exemple pour des impulsions clavier comme le passage à la ligne. Les signes entre 32 et 127 sont des signes pouvant être représentés parmi lesquels toutes les lettres, les chiffres et la ponctuation dont un américain a besoin (car le jeu de caractères ASCII vient naturellement des USA).
Pendant longtemps, ASCII était le seul standard répandu. Étant donné que les ordinateurs les plus récents ont des octets permettant 256 états, il était logique de trouver d'autre utilisations pour les valeurs entre 128 et 255. Là pourtant se développèrent des solutions spécifiques aux constructeurs. MS DOS utilise par exemple un "jeu de caractères ASCII étendu" qui n'est pas grand chose d'autre qu'une belle transcription pour l'occupation propre à Microsoft des signes 128 à 255 spéciale pour les besoins de MS-DOS.
Pour créer ici aussi un standard, l'organisation américaine de standardisation inventa le jeu de caractères ANSI. Ce jeu de caractères reprend pour les signes 0 à 127 le jeu de caractères ASCII et définit pour les valeurs entre 128 et 255 quantité de signes spéciaux parmi lesquels des signes importants de l'alphabet pour des langues répandues, par exemple les signes avec accent, les lettres avec accent en français ou les signes espagnols avec tilde. S'y ajoutent divers signes commerciaux ou scientifiques répandus.
La demande en jeux de caractères internationaux valables est pourtant toujours plus grande. Une tentative pour établir une telle collection de jeux de caractères est représentée par la ![]() famille iso-8859.
famille iso-8859.
|
|
Un exemple doit éclairer le principe des jeux de caractères. L' illustration suivante montre deux jeux de caractères: le jeu de caractères MS-DOS et le jeu de caractères ANSI que MS Windows par exemple utilise par défaut.
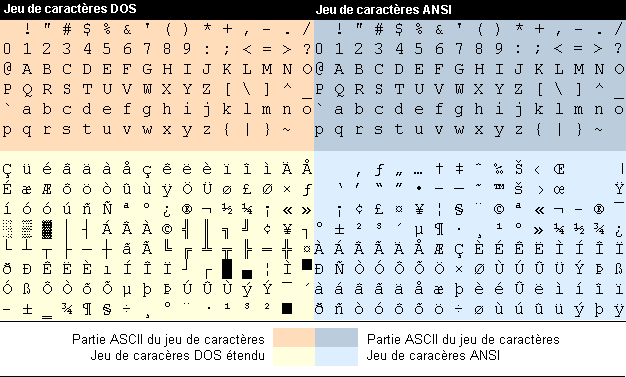
Vous pouvez constater sur l'illustration que les parties supérieures (plus sombres) des deux jeux de caractères sont identiques, étant donné que les deux jeux de caractères reprennent le jeu de caractères ASCII pour les 128 premiers signes (les 32 premiers signes manquent sur l'illustration étant donné qu'il s'agit pour ces signes de caractères de contrôle qui ne sont pas graphiques). Les parties inférieures (plus claires) sont par contre différentes. Là où dans le jeu de caractères ANSI par exemple se trouve un ú français minuscule, le jeu de caractères DOS étendu propose un tréma ¨.
Si vous travaillez avec MS Windows, vous pouvez expérimenter ça vous même: Créez sous MS Windows avec un éditeur de texte ANSI (par exemple le bloc notes) un fichier vide: frappez simplement quelque chose comme "ééééèùùùîîîî". Sauvegardez la saisie avec un nom de fichier. Ensuite appelez l'invite DOS (Commandes DOS) et entrez edit. Alors l'éditeur DOS s'ouvre. Ouvrez alors le fichier sauvegardé auparavant sous Windows. Maintenant vous pouvez voir quelle est la relation entre octet et jeu de caractères: Le même nombre de caractères que sous Windows est affiché mais les signes sont différents. La raison en est que dans la mémoire de travail ne se trouvent toujours que les valeurs d'octet. Ce qu'un programme en fait dépend du jeu de caractères qu'il utilise.
L'exemple entre le jeu de caractères MS-DOS et le jeu de caractères ANSI a été choisi ici intentionnellement étant donné qu'il est possible de la tester sur le même ordinateur. Mais l'exemple doit avant tout donner le courage d'aller plus loin dans les mystères des jeux de caractères et de de prendre conscience que rien de ce qui est affiché dans la fenêtre d'affichage ne coule de source mais que tout repose sur des conventions, qui d'un point de vue technique informatique reposent sur des bases bien plus profondes que HTML et autres langages Web standardisés.
|
|
Les jeux de caractères recouvrent des cultures distinctes de l'écriture et les langues ou familles de langues qui s'y rattachent. Cela devient problématique quand des documents en plusieurs langues doivent être établis qui contiennent des écritures de jeux de caractères tout à fait différents. Même pour les cultures de l'écriture non alphabétique, les jeux de caractères ne sont pas appropriés. À notre époque de la mondialisation il est pourtant toujours plus important de trouver une solution informatique technique standard pour de tels problèmes, solution qui s'impose aux systèmes informatiques les plus divers. Il existe déjà une telle solution: le ![]() système Unicode. Unicode doit à long terme remplacer le système habituel aujourd'hui des jeux de caractères. À l'heure actuelle, beaucoup de choses vont dans cette direction. Les systèmes d'exploitation récents proposent déjà la plupart du temps des polices qui ne sont plus limitées à un jeu de caractères mais qui couvrent le système complet de caractères Unicode ou tout au moins une grande partie de ce système. Même la plupart des applications modernes sauvegardent les textes non plus avec un octet par caractère mais avec deux octet par caractère. C'est ce qui donne la base du soutien du système Unicode.
système Unicode. Unicode doit à long terme remplacer le système habituel aujourd'hui des jeux de caractères. À l'heure actuelle, beaucoup de choses vont dans cette direction. Les systèmes d'exploitation récents proposent déjà la plupart du temps des polices qui ne sont plus limitées à un jeu de caractères mais qui couvrent le système complet de caractères Unicode ou tout au moins une grande partie de ce système. Même la plupart des applications modernes sauvegardent les textes non plus avec un octet par caractère mais avec deux octet par caractère. C'est ce qui donne la base du soutien du système Unicode.
|
|
Les polices sont des modèles de description pour représenter les signes sur les périphériques de sortie comme l'écran ou l'imprimante. Chaque système d'exploitation courant aujourd'hui contient ce qu'on appelle des polices système. Ce sont des polices qui contiennent en tous cas exactement les signes qui sont définis dans le jeu de caractères sur lequel le système se base par défaut. Sous MS Windows il existe par exemple une telle police nommée System. Par ailleurs, il existe sur les ordinateurs modernes des ports définis pour des polices au choix. Le port Adobe est par exemple répandu pour des polices (PostScript). Sous MS Windows vient en plus un port distinct (TrueType).
De telles polices peuvent poser des modèles de représentation quelconques sur les valeurs d'octets disponibles. Ainsi il existe également des polices comme WingDings ou ZapfDingbats, qui ne contiennent presque exclusivement que des symboles et des icônes. Pourtant sont importantes avant tout les polices qui certes sont évocatrices mais qui en même temps soutiennent un certain jeu de caractères, c'est à dire qui représentent tous les signes de ce jeu de caractères et cela exactement aux valeurs d'octet qui sont prévues à cet effet dans le jeu de caractères. Ce n'est que par de telles polices qu'il est possible de représenter graphiquement des jeux de caractères donnés. L'illustration suivante montre un exemple pour ce contexte:

Pour les polices modernes qui couvrent tout le système Unicode, le principe est le même. À la différence près que ce ne sont pas seulement 256 caractères qui peuvent y être adressés mais à l'heure actuelle jusqu'à 65536 caractères et à l'avenir encore beaucoup plus pour la simple raison que deux ou même quatre octets sont employés ce qui rend possibles des valeurs bien plus élevées que 256.
|
|
Étant donné que l'industrie informatique vit le jour aux USA et en Europe d'un point de vue historique, les systèmes matériels et systèmes d'exploitation actuels sont fondés sur des principes qui d'abord coulaient de source. Quand dans un programme de traitement de texte, vous frappez un texte, le curseur se déplace pendant la frappe de gauche à droite. Les césures se font se font selon les délimiteurs typiques des langues de l'ouest comme l'espace ou le trait d'union.
l y a pourtant quantité de cultures de l'écriture qui ont une direction d'écriture différente de la notre. À ces cultures appartiennent l'écriture arabe, l'écriture hébra�que et les cultures de l'écriture de l'extrême orient. Pour représenter sur des ordinateurs de telles cultures de l'écriture, des propriétés supplémentaires du logiciel sont indispensables. Car il n'est pas seulement question de représenter les éléments d'écriture mais aussi d'adapter à la culture d'écriture correspondante, la direction pour l'édition lors de la saisie et de la sortie sur des périphériques comme l'écran ou l'imprimante.
À cet effet existent en HTML des composantes du langage comme l'attribut universel dir= ou l'élément bdo, à l'aide desquels les auteurs de pages Web peuvent faire des mentions concernant le sens de l'écriture. La transcription côté logiciel "on the fly" sans qu'il soit indispensable d'installer un logiciel spécial supplémentaire fonctionne aussi déjà en partie pour les navigateurs récents.
|
| |
© 2001 Stefan Münz / © 2003 Traduction ![]() Serge François, 13405@free.fr
Serge François, 13405@free.fr![]() selfhtml@selfhtml.com.fr
selfhtml@selfhtml.com.fr